The Kubernetes Master node is one that runs what are known as the master processes: The kube-apiserver, kube-controller-manager and kube-scheduler.
In this post we’ll go through some common setup that all nodes (masters and workers) in your cluster should get, and then on top of that, the specific setup that will finally configure a single node in the cluster to be the master.
If you would like to jump to the other partes in this series, here are the links:
- Building a Raspberry Pi Kubernetes Cluster – Part 1 – Routing
- Building a Pi Kubernetes Cluster – Part 3 – Worker Nodes and MetalLB
- Raspberry Pi Kubernetes Cluster with OpenFaaS for Serverless Functions (Part 4)
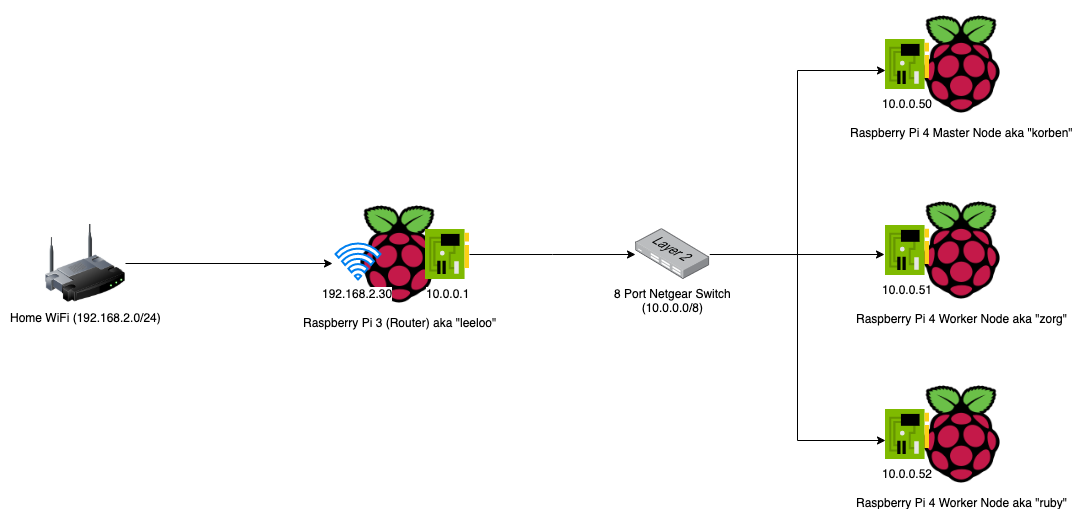
By now you should have some sort of stack or collection of Raspberry Pis going. As mentioned in the previous post, I used a Raspberry Pi 3 for my router/dhcp server for the Kubernetes Pi Cluster network, and Raspberry Pi 4’s with 4GB RAM each for the master and worker nodes. Here is how my stack looks now:

Common Setup
This setup will be used for both masters and workers in the cluster.
Start by writing the official Raspbian Buster Lite image to your microSD card. (I used the 26th September 2019 version), though as you’ll see next I also updated the Pi’s firmware and OS using the rpi-update command.
After attaching your Pi (master) to the network switch, it should pick up an IP address from the DHCP server you setup in part 1.
SSH into the Pi and complete the basic setup such as setting a hostname and ensuring it gets a static IP address lease from DHCP by editing your dnsmasq configuration (as per part 1).
Note: As the new Pi is running on a different network behind your Pi Router, you can either SSH into your Pi Router (like a bastion host or jump box) and then SSH into the new Master Pi node from there.
Now update it:
sudo rpi-update
After the update completes, reboot the Pi.
sudo reboot now
SSH back into the Pi, then download and install Docker. I used version 19.03 here, though at the moment it is not ‘officially’ supported.
export VERSION=19.03 curl -sSL get.docker.com | sh && sudo usermod pi -aG docker && newgrp docker
Kubernetes nodes should have swap disabled, so do that next. Additionally, you’ll enable control groups (cgroups) for resource isolation.
sudo dphys-swapfile swapoff sudo dphys-swapfile uninstall sudo update-rc.d dphys-swapfile remove sudo systemctl disable dphys-swapfile.service sudo sed -i -e 's/$/ cgroup_enable=cpuset cgroup_memory=1 cgroup_enable=memory/' /boot/cmdline.txt
Installing kubeadm and other Kubernetes components
Next you’ll install the kubeadm tool (helps us create our cluster quickly), as well as a bunch of other components required, such as the kubelet (the main node agent that registers nodes with the API server among other things), kubectl and the kubernetes cni (to provision container networking).
Next up, install the legacy iptables package and setup networking so that it traverses future iptables rules.
Note: when I built my cluster initially I discovered problems with iptables later on, where the kube-proxy and kubelet services had trouble populating all their required iptables rules using the pre-installed version of iptables. Switching to legacy iptables fixed this.
The error I ran into (hopefully those searching it will come across this post too) was:
proxier.go:1423] Failed to execute iptables-restore: exit status 2 (iptables-restore v1.6.0: Couldn't load target `KUBE-MARK-DROP':No such file or directory
Setup iptables and change it to the legacy version:
sudo sysctl net.bridge.bridge-nf-call-iptables=1 sudo update-alternatives --set iptables /usr/sbin/iptables-legacy
Lastly to finish off the common (master or worker) node setup, reboot.
sudo reboot now
Master Node Setup
Now you can configure this Pi as a master Kubernetes node. SSH back in after the reboot and pull down the various node component docker images, then initialise it.
Important: Make sure you change the 10.0.0.50 IP address in the below code snippet to match whatever IP address you reserved for this master node in your dnsmasq leases configuration. This is the IP address that the master API server will advertise out with.
Note: In my setup I am using 192.168.0.0./16 as the pod CIDR (overlay network). This is specifically to keep it separate from my internal Pi network of 10.0.0.0/8.
sudo kubeadm config images pull -v3 sudo kubeadm init --token-ttl=0 --apiserver-advertise-address=10.0.0.50 --pod-network-cidr=192.168.0.0/16 # capture text and run as normal user. e.g.: # mkdir -p $HOME/.kube # sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config # sudo chown $(id -u):$(id -g) $HOME/.kube/config
Once the kubeadm commands complete, the init command will output a bunch of commands to run. Copy and enter them afterwards to setup the kubectl configuration under $HOME/.kube/config.
You’ll also see a kubeadm join command/token. Take note of that and keep it safe. You’ll use this to join other workers to the cluster later on.
kubeadm join 10.0.0.50:6443 --token yi4hzn.glushkg39orzx0fk \
--discovery-token-ca-cert-hash sha256:xyz0721e03e1585f86e46e477de0bdf32f59e0a6083f0e16871ababc123
Installing the CNI (Weave)
You’ll setup Weave Net next. At a high level, Weave Net creates a virtual container network that connects your containers that are scheduled across (potentially) many different hosts and enables their automatic discovery across these hosts too.
Kubernetes has a pluggable architecture for container networking, and Weave Net is one implementation of this.
Note: the command below assumes you’re using an overlay/container network of 192.168.0.0/16. Change this if you’re not using this range.
On your Pi master node:
curl --location -o ./weave-cni.yaml "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')&env.IPALLOC_RANGE=192.168.0.0/16" kubectl apply -f ./weave-cni.yaml
After a few moments waiting for your node to pull down the weave net container images, check that the weave container(s) are running and that the master node is showing as ready. Here is how that should look…
kubectl -n kube-system get pods kubectl get nodes
pi@korben:~ $ kubectl -n kube-system get pods | grep weave weave-net-cfxhr 2/2 Running 20 10d weave-net-chlgh 2/2 Running 17 23d weave-net-rxlg8 2/2 Running 13 23d pi@korben:~ $ kubectl get nodes NAME STATUS ROLES AGE VERSION korben Ready master 23d v1.16.2
That is pretty much it for the master node setup. You now have a single master node running the Kubernetes master components / API server, and have even used to successfully provision and configure container networking.
As a result of deploying Weave Net, you now have a DaemonSet that will ensure that any new node that joins the cluster will automatically get the Weave Net CNI. All other nodes in the cluster will automatically update to ‘know’ about the new node and subsequently containers in the cluster will be able to talk to each other over the overlay network.