Introduction
Recently I was tasked with setting up a couple of new Kubernetes clusters for a team of developers to begin transitioning an older .NET application over to .NET Core 2.0. Part of my this work lead me down the route of trying out some different authentication strategies.
I ended on RBAC being a good solution for our needs allowing for nice role based permission flexibility, but still needed a way of handling authentication for users of the Kubernetes clusters. One of the options I looked into here was to use Kubernetes’ support for webhook token authentication.
Webhook token authentication allows a remote service to authenticate with the cluster, meaning we could hand off some of the work / admin overhead to another service that implements part of the solution already.
Testing Different Solutions
I found an interesting post about setting up Github with a custom webhook token authentication integration and tried that method out. It works quite nicely and some good benefits as discussed in the post linked before, but summarised below:
- All developers on the team already have their own Github accounts.
- Reduces admin overhead as users can generate their own personal tokens in their Github account and can manage (e.g. revoke/re-create) their own tokens.
- Flexible as tokens can be used to access Kubernetes via kubectl or the Dashboard UI from different machines
- An extra one I thought of – Github teams could potentially be used to group users / roles in Kubernetes too (based on team membership)
As mentioned before, I tried out this custom solution which was written in Go and was excited about the potential customisation we could get out of it if we wanted to expand on the solution (see my last bullet point above).
However, I was still keen to play around with Kubernetes’ Webhook Token Authentication a bit more and so decided to reimplement this solution in a language I am more familiar with. .NET Core would have been a good candidate, but I didn’t have a lot of time at hand and thought doing this in NodeJS would be quicker.
With that said, I rewrote the Github Webhook Token Authenticator service in NodeJS using a nice lightweight node alpine base image and set things up for Docker builds. Basically readying it for deployment into Kubernetes.
Implementing the Webhook Token Authenticator service in NodeJS
The Webhook Token Authentication Service simply implements a webhook to verify tokens passed into Kubernetes.
On the Kubernetes side you just need to deploy the DaemonSet with this authenticator docker image, run your API servers with RBAC enabled
Create a DaemonSet to run the NodeJS webhook service on all relevant master nodes in your cluster.
Here is the DaemonSet configuration already setup to point to the correct docker hub image.
Deploy it with:
kubectl create -f .\daemonset.yaml
Use the following configurations to start your API servers with:
authentication-token-webhook-config-file authentication-token-webhook-cache-ttl
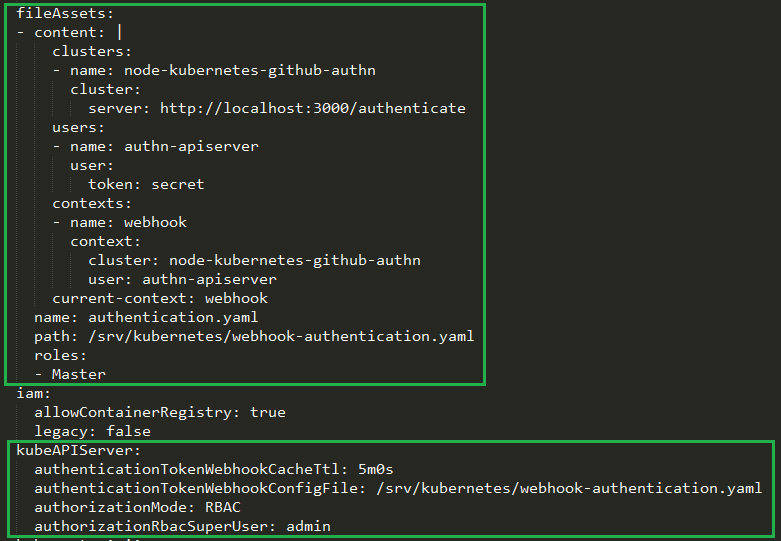
Update your cluster spec to add a fileAsset entry and also point to the authentication token webhook config file that will be put in place by the fileAsset using the kubeAPIServer config section.
You can get the fileAsset content in my Github repository here.
Here is how the kubeAPIServer and fileAssets sections should look once done. (I’m using kops to apply these configurations to my cluster in this example).
You can then set up a ClusterRole and ClusterRoleBinding along with usernames that match your users’ actual Github usernames to set up RBAC permissions. (Going forward it would be great to hook up the service to work with Github teams too.)
Here is an example ClusterRole that provides blanket admin access as a simple example.
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: youradminsclusterrole
rules:
- apiGroups: ["*"]
resources: ["*"]
verbs: ["*"]
- nonResourceURLs: ["*"]
verbs: ["*"]
Hook up the ClusterRole with a ClusterRoleBinding like so (pointing the user parameter to the name of your github user account you’re binding to the role):
kubectl create clusterrolebinding yourgithubusernamehere-admin-binding --clusterrole=youradminsclusterrole --user=yourgithubusernamehere
Don’t forget to create yourself (in your Github account), a personal access token. Update your .kube config file to use this token as the password, or login to the Kubernetes Dashboard UI and select “Token” as the auth method and drop your token in there to sign in.
The auth nodes running in the daemonset across cluster API servers will handle the authentication via your newly configured webhook authentication method, go over to Github, check that the token belongs to the user in the ClusterRoleBinding (of the same github username) and then use RBAC to allow access to the resources specified in your ClusterRole that you bound that user to. Job done!
For more details on how to build the NodeJS Webhook Authentication Docker image and get it deployed into Kubernetes, or to pull down the code and take a look, feel free to check out the repository here.