I’ve recently built myself a Kubernetes (1.16.2) cluster running on a combination of Raspberry Pi 4 and 3 devices.

I’ll be running through the steps I took to build it out in this series, with part 1 focusing on the router and internal node network side of things.
If you want to jump to the other parts in this series:
- Building a Raspberry Pi Kubernetes Cluster – Part 2 – Master Node
- Building a Pi Kubernetes Cluster – Part 3 – Worker Nodes and MetalLB
- Raspberry Pi Kubernetes Cluster with OpenFaaS for Serverless Functions (Part 4)
First off, here is a list of parts I used to set everything up:
- 1 x Raspberry Pi 3 (1GB) device for the router (this maintains a WiFi connection to my home network using the built-in WiFi and routes between this and the Ethernet device (eth0) which joins it to the Kubernetes network
- 3 x Raspberry Pi 4 (4GB) devices. 1 x master node, 2 x worker nodes
- 4 x SanDisk Ultra 32 GB microSDHC Memory Cards (Class 10)
- 1 x GeeekPi Pi Rack Case (Comes with a stack for 4 x Raspberry Pi’s, plus heatsinks and fans that support both models of Raspberry Pi I am using)
- 1 x Netgear GS208 8 port Gigabit Ethernet Switch (nice and cheap, but reliable). This is for connecting all the Raspberry Pi Ethernet interfaces to one network.
- 1 x Anker PowerPort 10 (10 port USB power supply)
- 5 x pack of RJ45 flat ribbon Ethernet Cables (0.5 meter length)
- 5 x pack of USB C short cables
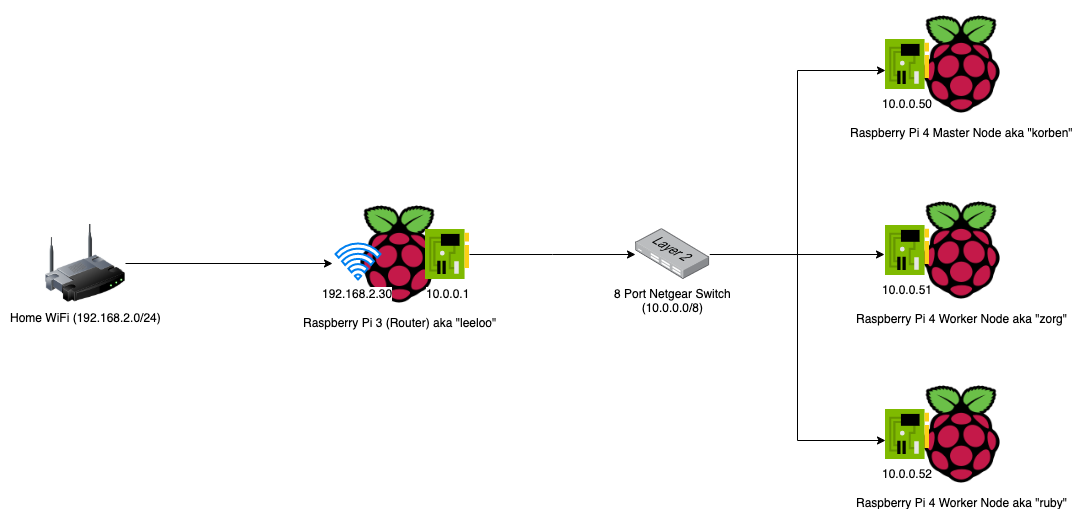
To make the setup as portable as possible, and also slightly seggregated from my home network, I used the 1 x Raspberry Pi 3 device I had as a router between my home network and my Kubernetes Layer 2 Network (effectively the devices on the 8 port Netgear Switch).
Here is a network diagram that shows the setup.
Building the Raspberry Pi Cluster Router
Of course you’ll need an OS on the microSD card for each Raspberry Pi you’re going to be using. I used the latest Raspbian Buster Lite image from the official Raspbian Downloads page (September 26).
This is a minimal image and is exactly what we need. You’ll need to write it to your microSD card. There are plenty tutorials out there on doing this, so I won’t cover it here.
One piece of advice though, would be to create a file called “ssh” on the imaged card filesystem after writing the image. This enables you to SSH on directly without the need to connect up a screen and setup the SSH daemon yourself. Basically just login to your home network DHCP server and look for the device once it boots then SSH to it’s automatically assigned IP address.
Also, it would be wise to reserve an IP address on your home network’s DHCP service for your Pi Router. Grab the MAC address of your Pi and add it to your home network DHCP service’s reserved IP addresses. I set mine to 192.168.2.30 on my WiFi network.
List the wlan interface’s MAC address with:
ifconfig wlan0
Setting Hostname and Changing the Default Password
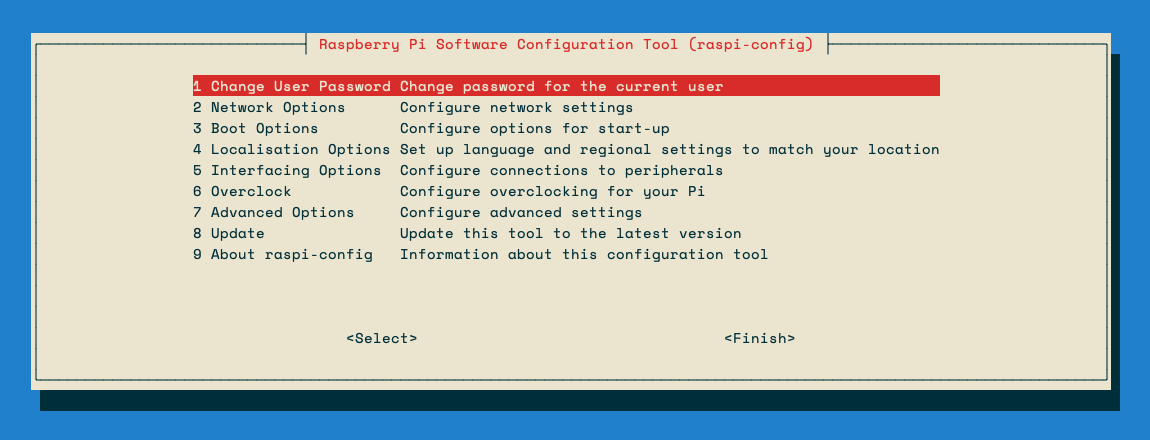
On the Router Raspberry Pi, run the following command to change the hostname to something other than “raspberry” and change the default password too:
sudo raspi-config
Setting up the Pi Router
Now the rest of the guide deserves much credit to this blog post, however, I did change a few things on my setup, as the routing was not configured 100% correctly to allow external access to services on the internal Kubernetes network.
I needed to add a couple of iptables rules in order to be able to access my Ingress Controller from my home network. More on that later though.
Interface Setup
You need to configure the WiFi interface (wlan0) and the Ethernet Interface (eth0) for each “side” of the network.
Edit the dhcpd.conf file and add an eth0 configuration right at the bottom, then save.
sudo nano /etc/dhcpcd.conf
interface eth0 static ip_address=10.0.0.1/8 static domain_name_servers=1.1.1.1,208.67.222.222 nolink
Of course replace the above DNS servers with whichever you prefer to use. I’ve used Cloudflare and OpenDNS ones here.
Next, setup your WiFi interface to connect to your home WiFi. WiFi connection details get saved to /etc/wpa_supplicant/wpa_supplicant.conf but it is best to use the built-in configuration tool (raspi-config) to do the WiFi setup.
sudo raspi-config
Go to Network Options and enter your WiFi details. Save/Finish afterwards.
Install and Configure dnsmasq
sudo apt update sudo apt install dnsmasq sudo mv /etc/dnsmasq.conf /etc/dnsmasq.conf.backup
Create a new /etc/dnsmasq.conf file with the below command:
The script is the main dnsmasq configuration that sets DHCP up over the eth0 interface (for the 10.0.0.0/8 network side) and configures some nameservers for DNS as well as a few other bits.
Edit the service file for dnsmasq (/etc/init.d/dnsmasq) to prevent issues with start-up order of dnsmasq and dhcpcd:
sudo nano /etc/init.d/dnsmasq
Change the top of the file to look like this:
#!/bin/sh # Hack to wait until dhcpcd is ready sleep 10 ### BEGIN INIT INFO # Provides: dnsmasq # Required-Start: $network $remote_fs $syslog $dhcpcd # Required-Stop: $network $remote_fs $syslog # Default-Start: 2 3 4 5 # Default-Stop: 0 1 6 # Description: DHCP and DNS server ### END INIT INFO
The lines changed above are the sleep 10 command and the Required-Start addition of $dhcpcd.
At this point its a good idea to reboot.
sudo reboot now
After the reboot, check that dnsmasq is running.
sudo systemctl status dnsmasq
Setup iptables
First of all, enable IP forwarding. Edit the /etc/sysctl.conf file and uncomment this line:
net.ipv4.ip_forward=1
This enables us to use NAT rules with iptables.
Now you’ll configuring some POSTROUTING and FORWARD rules in iptables to allow your Raspberry Pi devices on the 10.0.0.0/8 network to access the internet via your Pi Router’s wlan0 interface.
sudo iptables -t nat -A POSTROUTING -o wlan0 -j MASQUERADE sudo iptables -A FORWARD -i wlan0 -o eth0 -m state --state RELATED,ESTABLISHED -j ACCEPT sudo iptables -A FORWARD -i eth0 -o wlan0 -j ACCEPT
Optional Step
This is optional, and you might only need to do this later on once you start running services in your Kubernetes Pi Cluster.
Forward Traffic from your home network to a Service or Node IP in your Cluster Network:
sudo iptables -t nat -A PREROUTING -i wlan0 -p tcp --dport 80 -j DNAT --to-destination 10.23.220.88:80 sudo iptables -t nat -A POSTROUTING -p tcp -d 10.23.220.88 --dport 80 -j SNAT --to-source 10.0.0.1
The above assumes a couple of things that you should change accordingly (if you use this optional step):
- You have a Service running in the Kubnernetes network, listening on port 80 (http) on IP 10.23.220.88
- You setup your Pi Router to use 10.0.0.1 as the eth0 device IP (as per above in this post), and your wlan0 interface is the connection that your Pi router is using to connect to your home network (WiFi).
- You actually want to forward traffic hitting your Pi Router (from the WiFi wlan0 interface) through the 10.0.0.1 eth0 interface and into a service IP on the 10.0.0.0/8 network. (In my example above I have an nginx Ingress Controller running on 10.23.220.88).
Persisting your iptables rules across reboots
Persist all of your iptables rules by installing iptables-persistent:
sudo apt install iptables-persistent
The above will run a wizard after installation and you’ll get the option to save your IPv4 rules. Choose Yes, then reboot afterwards.
After reboot, run sudo iptables -L -n -v to check that the rules persisted after reboot.
Note: if you ever update your Pi Router’s iptables rules and want to re-save the new set of rules to persist across reboots, you’ll need to re-save them using the iptables-persistent package.
sudo dpkg-reconfigure iptables-persistent
Adding new Pi devices to your network in future
Whenever you add an additional Raspberry Pi device to the 8 port switch / Kubernetes network in the future, make sure you edit /etc/dnsmasq.conf to update the list of MAC addresses assigned to 10.0.0.x IP addresses.
You’ll want to set the new Pi’s eth0 MAC address up in the list of pre-defined DHCP leases.
You can also view the /var/lib/misc/dnsmasq.leases file to see the current dnsmasq DHCP leases.
This is handy when adding a new, un-configured Pi to the network – you can pick up the auto-assigned IP address here, and then SSH to that for initial configuration.
Concluding
That is pretty much the setup and configuration for the Pi Router complete. As mentioned above, much credit for this configuration goes to this guide on downey.io.
I ended up modifying the iptables rules for service traffic forwarding from my home network side into some Kubernetes LoadBalancer services I ended up running later on which I covered above in the Optional Steps section.
At this point you should have your Pi Router connected to your home network via WiFi, and have the Ethernet port plugged into your network switch. Make sure the switch is not connected back to your home network via an Ethernet cable or you’ll run into some strange network loop issues.
You should now be able to plug in new Pi’s to the network switch, and they should get automatically assigned DHCP addresses on the 10.0.0.0/8 network.
Updating your dnsmasq.conf file with the new Pi’s ethernet MAC addresses means that they can get statically leases IP addresses too, which you’ll need for your Kubernetes nodes once you start adding them (see Part 2 coming next).