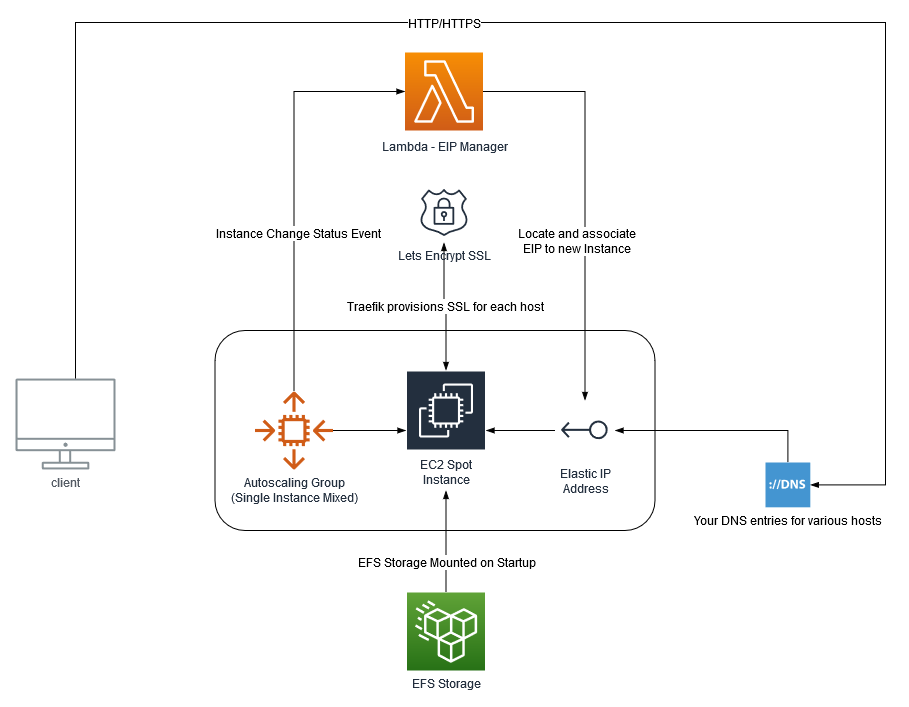
This post contains my ffmpeg cheat sheet.
ffmpeg is a very useful utility to have installed for common audio and video conversion and modification tasks. I find myself using it frequently for both personal and work use.
Got an audio or video file to compress or convert? Or maybe you’re looking to split off a section of a video file. Did you do a screen recording of a meeting session and find you need to share it around, but it’s way too large in filesize?
ffmpeg is the clean and easy command line approach. I’ve put together a ffmpeg cheat sheet below that has some quick and easy usages documented.
Skip ahead to the ffmpeg Cheat Sheet section below if you already have it installed and ready to go.
Installing ffmpeg (macOS / Windows)
On macOS, you’re best off using homebrew. If you don’t have homebrew already, go get that done first. Then:
macOS
brew install ffmpeg
Windows
You can grab a release build in 7-zip archive format from here (recent as of the publish date of this post). Be sure to check the main ffmpeg downloads page for newer builds if you’re reading this page way in the future.
If you don’t have 7-zip, download and install that first to decompress the downloaded ffmpeg release archive.
Now you’ll ideally want to update your user PATH to include the path that you’ve extracted 7-zip to. Make sure you’ve moved it to a convenient location. For example on my Windows machine, I keep ffmpeg in D:\Tools\ffmpeg.
Open PowerShell (Windows key + R), type powershell, hit enter.
To ensure that the path persists whenever you run powershell in the future, in powershell, run:
notepad $profile
This will load a start-up profile for powershell in notepad. If it doesn’t exist yet, it’ll prompt you to create a new file. Choose yes.
In your profile notepad window, enter the following, replacing D:\Tools\ffmpeg with the path you extracted ffmpeg to on your own machine.
[Environment]::SetEnvironmentVariable("PATH", "$Env:PATH;D:\tools\ffmpeg")
Close Notepad and save the changes. Close Powershell, then launch it again. This time if you type ffmpeg in the powershell window you’ll run it, no matter which directory you’re in.
ffmpeg Cheat Sheet
This is a list of my 10 most useful ffmpeg commands for conversion and modification of video and audio files.
| Task Description | Command |
| Convert a video from MP4 to AVI format | ffmpeg -i inputfile.mp4 outputfile.avi |
| Trim a video file (without re-encoding) | ffmpeg -ss START_SECONDS -i input.mp4 -t DURATION_SECONDS -c copy output.mp4 |
| Convert WAV audio file to compressed MP3 format | ffmpeg -i input.wave -acodec libmp3lame output.mp3 |
| Mux video from input1.mp4 with audio from input2.mp4 | ffmpeg -i input1.mp4 -i input2.mp4 -c copy -map 0:0 -map 1:1 -shortest output.mp4 |
| Resize or scale video from current size to 1280×720. | ffmpeg -i input.mp4 -s 1280x720 -c:a copy output.mp4 |
| Extract audio to MP3 from a video file | ffmpeg -i inputvideo.mp4 -vn -acodec libmp3lame outputaudio.mp3 |
| Add watermark or logo to the top-left of a video. (Change overlay parameter for different positions). | ffmpeg -i inputvideo.mp4 -i logo.png -filter_complex "overlay=5:5" -codec:a copy outputvideo.mp4 |
| Covert video to GIF | ffmpeg -i inputvideo.mp4 output.gif |
| Change the frame rate of a video | ffmpeg -i inputvideo.mp4 -filter:v 'fps=fps=15' -codec:a copy outputvideo.mp4 |
Bonus batch scripts for video file re-sizing below. For example, iterate over every .MP4 file in a directory and resize to 1080p, or every file prefixed with DJI_ and resize to 1440p:
for f in *.MP4 ; do ffmpeg -i "$f" -s 1920x1080 -c:a copy "resized-1080p-$f" ; done for f in DJI_* ; do ffmpeg -i "$f" -s 2560x1440 -c:a copy "resized-1440p-$f" ; done
This list doesn’t even scratch the surface of the capabilities of ffmpeg. If you dig deeper you’ll find commands and parameters for just every audio and video modification process you need.
Remember, while it’s often easy to find a free conversion tool online, there’ll always be a catch or risk of using these. Whether it’s being subjected to unecessary advertising, catching potential malware, or being tracked with 3rd party cookies, you always take risks using free online tools. I guarantee almost every single free conversion website is using ffmpeg on their backend.
So do yourself a favour and practice and using CLI tools to do things yourself.