Putting CloudFront in front of a static website that is hosted in an S3 bucket is an excellent way of serving up your content and ensuring it is geographically performant no matter where your users are by leveraging caching and CloudFront’s geographically placed edge locations. You can go one step further and customise your HTTP headers with Lambda@Edge and CloudFront.
The basic Cloudfront and S3 origin setup goes a little something like this:
- Place your static site files in an S3 bucket that is set up for static web hosting
- Create a CloudFront distribution that uses the S3 bucket content as the origin
- Add a cache behaviour to the distribution
This is an excellent way of hosting a website or webapp that can be delivered anywhere in the world with ultra low latency, and you don’t even have to worry about running your own webserver to host the content. Your content simply sits in an S3 bucket and is delivered by CloudFront (and can be cached too).
Modifying HTTP headers with Lambda@Edge and CloudFront
But what happens if you want to get a little more technical and serve up custom responses for any HTTP requests for your website content? Traditionally you’d need a custom webserver that you could use to modify the HTTP request/response lifecycle (such as Varnish / Nginx).
That was the case until Lambda@Edge was announced.
I was inspired to play around with Lambda@Edge after reading Julia Evan’s blog post about Cloudflare Workers, where she set up something similar to add a missing Content-Type header to responses from her blog’s underlying web host. I wanted to see how easy it was to handle in an AWS setup with S3 hosted content and CloudFront.
So here is a quick guide on how to modify your site / webapp’s HTTP responses when you have CloudFront sitting in front of it.
Note: you can run Lambda@Edge functions on all these CloudFront events (not just the one mentioned above):
- After CloudFront receives a request from a viewer (viewer request)
- Before CloudFront forwards the request to the origin (origin request)
- After CloudFront receives the response from the origin (origin response)
- Before CloudFront forwards the response to the viewer (viewer response)
- You can return a custom response from Lambda@Edge without even sending a request to the CloudFront origin at all.
Of course the only ones that are guaranteed to always run are the Viewer type events. This is because origin request and origin response events only happen when the requested object is not already cached in an edge location. In this case CloudFront forwards a request to the origin and will receive a response back from the origin (hopefully!), and these events you can indeed act upon.
How to edit HTTP responses with Lambda@Edge
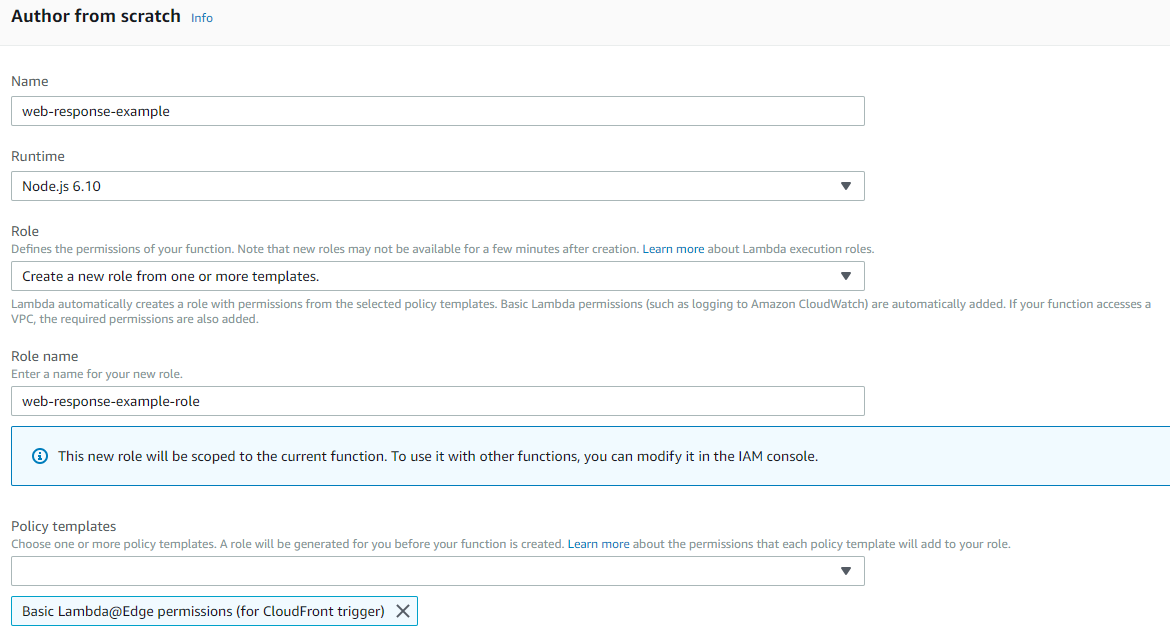
Create a new Lambda function and make sure it is placed in the us-east-1 region. (There is a requirement here by AWS that the function must be created in the US East / N. Virginia Region). When you create the function, it is deployed to all regions across the world with their own replication version of the Lambda@Edge function.
Fun fact: your CloudWatch logs for Lambda@Edge will appear in the relevant region where your content is requested from – i.e. based on the region the edge location exists in that ends up serving up your content.
You’ll need to create a new IAM Role for the function to leverage, so use the Lambda@Edge role template.
Select Node 6.10 runtime for the function. In the code editor, setup the following Node.js handler function which will do the actual header manipulation work:
exports.handler = (event, context, callback) => {
const response = event.Records[0].cf.response;
const headers = response.headers;
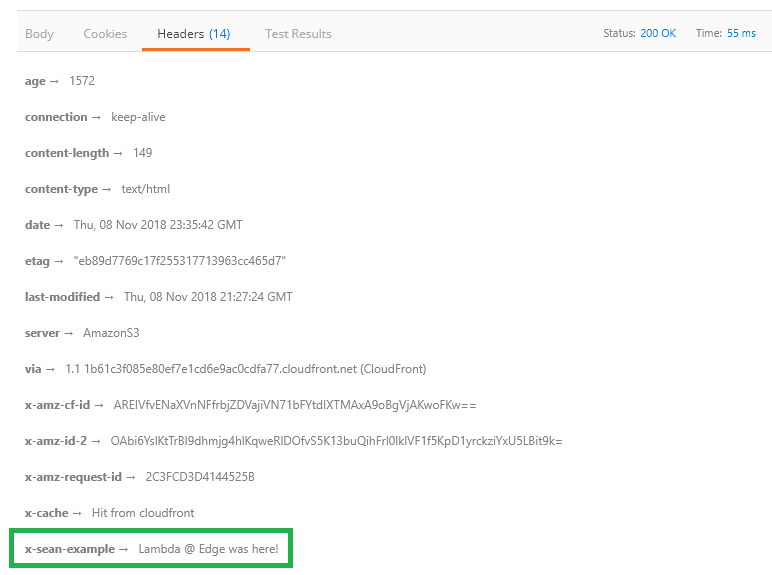
headers['x-sean-example'] = [{key: 'X-Sean-Example', value: 'Lambda @ Edge was here!'}];
callback(null, response);
};
The function will receive an event for every request passing through. In that event you simply retrieve the CloudFront response event.Records[0].cf.response and set your required header(s) by referencing the key by header name and setting the value.
Make sure you publish a version of the Lambda function, as you’ll need to attach it to your CloudFront behavior by ARN that includes the version number. (You can’t use $LATEST, so make sure you use a numerical version number that you have published).

Now if you make a new request to your content, you should see the new header being added by Lambda@Edge!
Lambda@Edge is a great way to easily modify CloudFront Distribution related events in the HTTP lifecycle. You can keep response times super low as the Lambda functions are executed at the edge location closest to your users. It also helps you to keep your infrastructure as simple as possible by avoiding the use of complicated / custom web servers that would otherwise just add unecessary operational overhead.